
What ChatGPT, Claude, Gemini, Grok & Perplexity Are Actually Trained On—And Why It Matters for Every Early-Stage SaaS Executive
LLM Training Data: The Hidden Architecture Behind Every AI Recommendation
LLM training data is the raw material that determines whether your SaaS company exists in the mind of an AI—or doesn’t. When a prospective enterprise buyer asks ChatGPT to recommend the best accounts payable automation software, the model does not search the internet in real time. It retrieves from memory—a compressed, weighted representation of billions of documents it was trained on. If your company is not in that training data, it is not on the shortlist. It never existed.
This is not a theoretical concern. According to Q1 2026 industry data, 51% of B2B software buyers now initiate their research journey inside an AI chatbot. That figure translates directly into a structural question every early-stage SaaS executive and investor should be asking: what sources did the five major AI models—ChatGPT, Claude, Gemini, Grok, and Perplexity—actually train on, and can your company’s content reach them?
The answer is far more opaque than most founders realize. LLM developers publish almost nothing about their specific training corpora. What is known comes from model cards, research papers, licensing disclosures, and inference from observed behavior. What DevelopmentCorporate has done is synthesize that evidence into a 42-source intelligence map—a practical guide for founders and investors who need to understand where AI models learn about the world and, by extension, where your company needs to show up.
“If your company is not in an LLM’s training data, it is not on the shortlist. It never existed.”
How LLM Training Data Actually Works
At its core, a large language model is trained by exposing it to an enormous corpus of text—web pages, books, code repositories, academic papers, forums, news articles—and teaching it to predict the next word in a sequence. Through billions of iterations of this prediction task, the model develops an internal representation of language, facts, relationships, and reasoning patterns.
The key insight for SaaS executives is that this process is not continuous or real-time. Training is a discrete event. A dataset is assembled, the model is trained on it over weeks or months using massive computational resources, and the resulting weights are frozen. Everything the model knows comes from that fixed training window. Content published after the training cutoff does not exist in the model’s memory—regardless of how authoritative, relevant, or widely cited it might be.
After this initial pretraining, developers apply additional fine-tuning techniques—most commonly Reinforcement Learning from Human Feedback (RLHF) and its variants—to align the model with user preferences, improve factual accuracy, and reduce harmful outputs. These fine-tuning stages shape how a model communicates, but they do not fundamentally expand what it knows about the world. The training data remains the foundation.
The Five Major LLMs: A Training Architecture Snapshot
Each of the five major AI models takes a meaningfully different approach to training, fine-tuning, and knowledge currency. Here is a summary drawn from published model cards, research disclosures, and DevelopmentCorporate’s LLM Training Data Matrix.
ChatGPT (OpenAI GPT-5.5) has a training knowledge cutoff of December 2025. OpenAI applies iterative Reinforcement Learning from Human Feedback at massive scale, with a large-scale preference modeling layer that shapes response quality and citation behavior. ChatGPT benefits from Bing integration for search-augmented responses but defaults to training memory for most queries. ChatGPT has the broadest confirmed training corpus among the static-cutoff models.
Claude (Anthropic 4.7 Opus) has a training knowledge cutoff of January 2026—the most recent static cutoff in this comparison. Anthropic trains Claude using Constitutional AI, a framework that bakes safety and value alignment into the training process itself, supplemented by Reinforcement Learning from AI Feedback (RLAIF). Paradoxically, despite its recency, Claude presents the most opaque training profile in DevelopmentCorporate’s 42-source analysis: zero confirmed training sources, with all coverage signals rated POSSIBLE or LIKELY based on inference rather than disclosure.
Gemini (Google 3.1 Pro) has a training knowledge cutoff of January 2025, making it the most dated static-cutoff model in this group. However, Gemini benefits from Google’s native search integration, which partially offsets the older training data for real-time queries. Gemini uses multi-stage fine-tuning and distributed RLHF, and its training corpus benefits from Google’s unique access to YouTube transcripts, Google Books, and Google Scholar—sources unavailable to competitors.
Grok (xAI 4.1) has a training knowledge cutoff of November 2024, but compensates through a structural advantage: real-time access to the X/Twitter firehose. Grok ingests the full X data stream continuously, meaning it has near-real-time awareness of conversations, announcements, and market developments on that platform. This makes Grok uniquely responsive to Twitter-native content and momentum signals—an important consideration for founders whose communities live on X.
Perplexity does not have a static knowledge cutoff in the traditional sense. Perplexity operates as a search-first AI—PerplexityBot actively crawls the public web continuously, indexing new content and surfacing it in responses with citations. This architecture means Perplexity can reference content published days or hours ago. For SaaS companies, this is the highest-ROI optimization target: content indexed by Perplexity achieves confirmed citation status faster than any other channel.
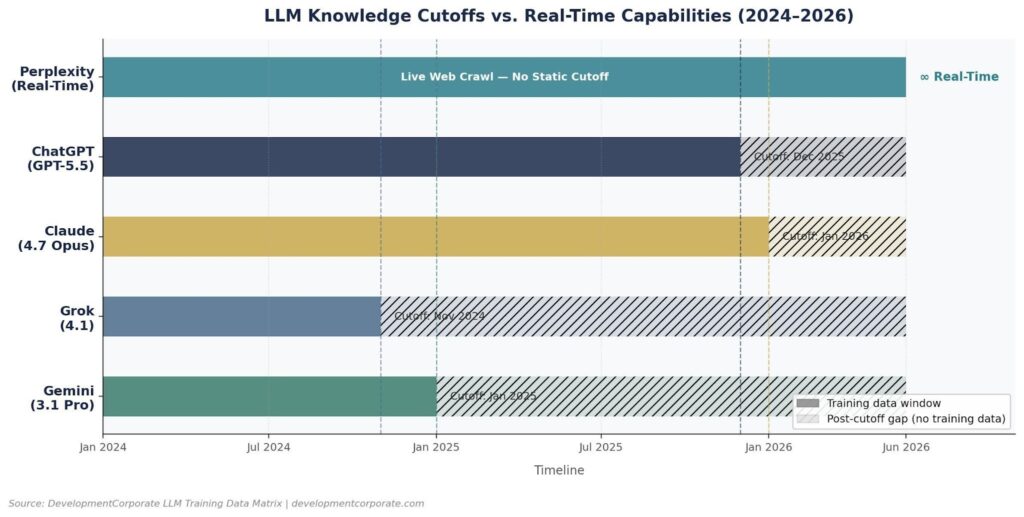
Figure 1: Knowledge cutoff windows for each major LLM. Perplexity operates with real-time crawl; all others have fixed training cutoffs. Source: DevelopmentCorporate LLM Training Data Matrix, 2026.
Knowledge Cutoffs vs. Real-Time Web Search: What’s the Difference?
One of the most misunderstood aspects of LLM behavior is the difference between training data—what the model memorized during pretraining—and real-time web search, which some models can perform at query time. These are fundamentally different mechanisms with different implications for SaaS visibility.
Static Training Data
When a user asks a model a question, the model’s default response comes from its training data—the frozen snapshot of the internet it was trained on up to its knowledge cutoff date. For ChatGPT (December 2025), Claude (January 2026), Gemini (January 2025), and Grok (November 2024), this means responses to non-search-triggered queries reflect the world as it existed at those dates. A SaaS company that was not visible in those training corpora does not get cited—even if it has since become a category leader.
Search-Augmented Responses
Several models now layer real-time web search on top of their training data for certain query types. ChatGPT can trigger Bing searches; Gemini can access Google Search; Perplexity is built entirely around web retrieval. According to analysis of ChatGPT query behavior, approximately 34.5% of ChatGPT queries trigger a live web search, meaning the model actively crawls the internet rather than answering purely from memory.
This creates a dual-layer optimization challenge. A SaaS company needs to be present in LLM training data to appear in non-search-triggered responses—the majority of enterprise discovery queries. And it needs to be well-indexed by search engines to appear in search-augmented responses. Excelling at one layer but not the other produces incomplete AI visibility.
The Grok Exception: Real-Time Firehose
Grok’s real-time access to the X/Twitter data stream is architecturally distinct from search augmentation. While ChatGPT and Gemini must trigger an explicit search to access fresh content, Grok continuously ingests X data. This means Grok’s knowledge of X-native content—product launches announced on X, community conversations, founder commentary—is perpetually current. For SaaS companies with active X presences, this is a meaningful visibility channel that other models cannot replicate from X content alone.
“A company that ranks on Google but doesn’t appear in ChatGPT responses loses the discovery step. A company in LLMs but not on Google loses the verification step. Both gaps produce the same outcome.”
The Opacity Problem: Why Nobody Knows What’s Actually in LLM Training Data
The most consequential fact about LLM training data is not what is in it. It is how little any of the major developers disclose about what is in it. This opacity is not accidental—it reflects commercial sensitivity, ongoing litigation risk, and competitive strategy. But it creates a structural problem for every SaaS company trying to manage its AI visibility.
OpenAI has disclosed that GPT models were trained on data from Common Crawl (a broad web crawl), books, Wikipedia, and other internet text. But it has published no source-level breakdown, no domain-level inclusion list, and no information about what content was downweighted or excluded. Anthropic has disclosed Constitutional AI methodology in research papers but has released no training corpus details. Google has referenced Google Books, Google Scholar, and YouTube in the context of Gemini but has not published a corpus breakdown. xAI has disclosed real-time X access but has not specified the scope of Grok’s pretraining corpus beyond broad web crawl.
The practical implication is that SaaS companies cannot know with certainty whether a specific piece of content—their blog, their Crunchbase profile, a TechCrunch article about their funding—is in any given model’s training data. What DevelopmentCorporate’s GEO Intelligence practice has done is develop a confidence-level framework—CONFIRMED, LIKELY, POSSIBLE, UNLIKELY, BLOCKED—based on available evidence from model cards, academic publications, verified licensing deals, crawler log analysis, and observed citation behavior.
For investors conducting M&A due diligence, this opacity is itself a finding. A target company’s LLM visibility is a valuation-relevant asset that cannot be verified through traditional channels. It requires a structured GEO audit—the kind of analysis detailed in DevelopmentCorporate’s
For investors conducting M&A due diligence, this opacity is itself a finding. A target company’s LLM visibility is a valuation-relevant asset that cannot be verified through traditional channels. It requires a structured GEO audit—the kind of analysis detailed in DevelopmentCorporate’s AI Search Visibility Audit framework.
The Source Intelligence Map: What’s Validated, Blocked, or Unknown Across Five LLMs
DevelopmentCorporate’s LLM Training Data Matrix maps 42 content sources across five major LLMs—ChatGPT, Claude, Gemini, Grok, and Perplexity—using a five-tier confidence scale. The findings are organized by source tier, weighted by strategic importance, and annotated with GTM implications for SaaS companies. Here is the intelligence across each category.
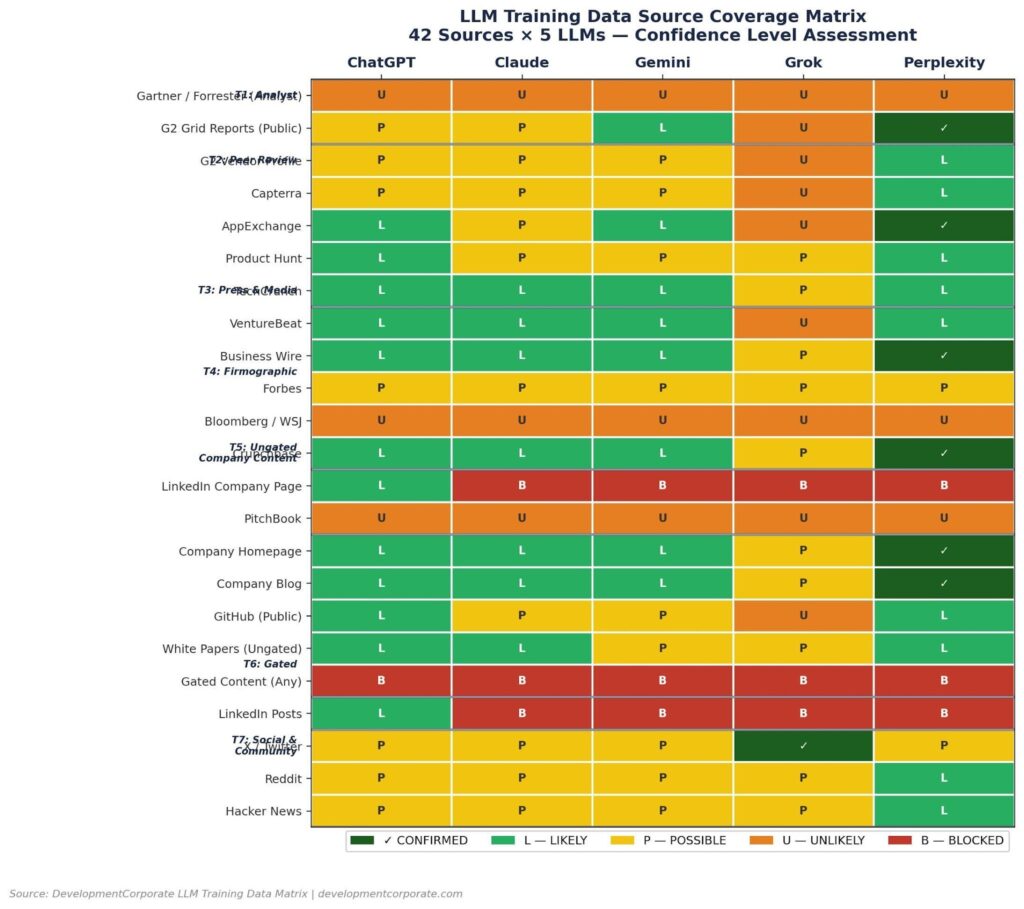
Figure 2: LLM Training Data Source Coverage Matrix. 42 sources × 5 LLMs. CONFIRMED (dark green) = verified in training or real-time index. BLOCKED (red) = technically inaccessible. Source: DevelopmentCorporate LLM Training Data Matrix, 2026.
Tier 1 — Analyst & Research Reports (Weight: 5×)
Gartner Magic Quadrant, Forrester Wave, IDC MarketScape, Celent, and Datos Insights reports are UNLIKELY or BLOCKED across all five LLMs. The paywall is absolute. LLM crawlers cannot access paywalled content, which means a SaaS company spending $50,000 on a Gartner Niche Player designation receives zero downstream citation benefit in AI-generated vendor comparisons. The sole Tier 1 exception is G2 Grid Reports—public category grids are indexed by all LLMs, with Perplexity showing a CONFIRMED status.
The strategic implication is direct: analyst report investment should be decoupled from AI visibility strategy. If Gartner placement is valuable for human analysts and procurement committees, pursue it—but do not expect it to move your LLM citation footprint. Invest separately in Tier 5 ungated content and Tier 3 press coverage for AI visibility.
Tier 2 — Peer Review Aggregators (Weight: 5×)
G2 vendor profiles, Capterra, TrustRadius, AppExchange, and Product Hunt are POSSIBLE to LIKELY across most LLMs. Perplexity actively cites AppExchange and G2 category pages. The key threshold finding: a vendor profile on G2 does not automatically generate LLM signal. DevelopmentCorporate’s analysis identifies a ~50-review threshold—models cite vendors confidently by name only when their G2 profiles have achieved meaningful review volume.
Product Hunt is an underappreciated Tier 2 asset. Launch posts are archived permanently and indexed by all LLMs. A Product Hunt launch generates a permanent citation asset—not just a day-of traffic spike. For early-stage SaaS companies, a well-executed Product Hunt launch is one of the highest-ROI GEO investments available.
Tier 3 — Earned Press & Tech Media (Weight: 4×)
TechCrunch and VentureBeat are LIKELY across ChatGPT, Claude, and Gemini, and LIKELY on Perplexity. Business Wire is CONFIRMED on Perplexity—wire service releases index within hours and compound training signal over time. Forbes is POSSIBLE across all LLMs. Bloomberg and WSJ are UNLIKELY or BLOCKED due to paywalls.
The practical ranking for Tier 3 GEO investment is: Business Wire > TechCrunch > VentureBeat > PR Newswire > Forbes for AI visibility. Vertical trade press (CoinDesk, Decrypt) scores LIKELY on Perplexity for crypto-adjacent SaaS categories—a meaningful signal for fintech and Web3 infrastructure companies.
Tier 4 — Funding & Firmographic Data (Weight: 2×)
Crunchbase is CONFIRMED on Perplexity and LIKELY across ChatGPT, Claude, and Gemini. It is the primary source for “Who is [company]?” queries—the first thing an AI checks when a user asks about an unfamiliar vendor. Completing a Crunchbase profile with accurate domain, founding date, funding history, and product description is a Day 1 GEO action for any SaaS company.
LinkedIn is the most significant structural asymmetry in the matrix. LinkedIn company pages are indexed by ChatGPT (via Bing partial access) but BLOCKED for Claude, Gemini, Grok, and Perplexity. LinkedIn has aggressively blocked crawlers to protect its data as a commercial asset. For SaaS companies that have invested heavily in LinkedIn content, this is a material finding: that content is invisible to four of the five major LLMs.
PitchBook is UNLIKELY across all five models—paywalled private company profiles do not reach LLM training corpora.
Tier 5 — Ungated Company Content (Weight: 3×, Perplexity: 5×)
Company homepages and ungated blog content are LIKELY across ChatGPT, Claude, and Gemini—and CONFIRMED on Perplexity. This is the highest-ROI training data tier for the majority of SaaS companies. Ungated technical white papers are LIKELY on ChatGPT and Claude. GitHub public repositories are confirmed GPT Codex training data and LIKELY on Perplexity—a critical signal for developer-facing and API-first products.
The economic case is clear: a blog post costs $500–$2,500 to produce and generates indefinite LLM signal across all five models. A gated white paper costs $10,000–$20,000 to produce and generates zero LLM signal. The ROI calculation does not require sophisticated modeling.
The critical caveat for Perplexity: PerplexityBot respects robots.txt. Any SaaS company that has added PerplexityBot to its robots.txt exclusion list is structurally invisible to Perplexity—the fastest-growing enterprise research AI. This is the single highest-priority technical check any SaaS company should complete today. See DevelopmentCorporate’s Gartner Blind Spots analysis for robots.txt audit instructions.
Tier 6 — Gated Content (Weight: 0×)
Gated white papers, gated case studies, webinars behind registration walls, and demo/trial pages are BLOCKED universally across all five LLMs. This is the most expensive mistake in enterprise SaaS content strategy. Content behind a form generates zero LLM training signal—regardless of its quality, depth, or strategic relevance.
The fix is structural, not cosmetic. Ungating existing content—converting gated PDFs to ungated HTML pages on the company domain, publishing ungated executive summaries alongside registration-required full reports, and creating ungated product overview pages as alternatives to demo walls—converts Tier 6 dead weight into Tier 5 training signal.
Tier 7 — Social & Community (Weight: 2×)
X/Twitter is the standout Tier 7 channel—CONFIRMED on Grok via real-time firehose access, and POSSIBLE across other LLMs. Reddit is LIKELY on Perplexity and POSSIBLE across ChatGPT, Claude, and Gemini—with crypto subreddits (r/Bitcoin, r/ethereum) generating particularly strong citation signals for fintech and Web3 SaaS companies. Hacker News is LIKELY on Perplexity and POSSIBLE across other models, with “Show HN” posts for open-source projects generating confirmed GPT and Perplexity training signal.
LinkedIn posts, like LinkedIn pages, are indexed only by ChatGPT (Bing) and BLOCKED for the other four LLMs. Discord and Telegram communities have minimal current LLM citation signal—lower authority than Reddit or Hacker News. Podcast pages generate limited signal unless transcripts are published ungated.
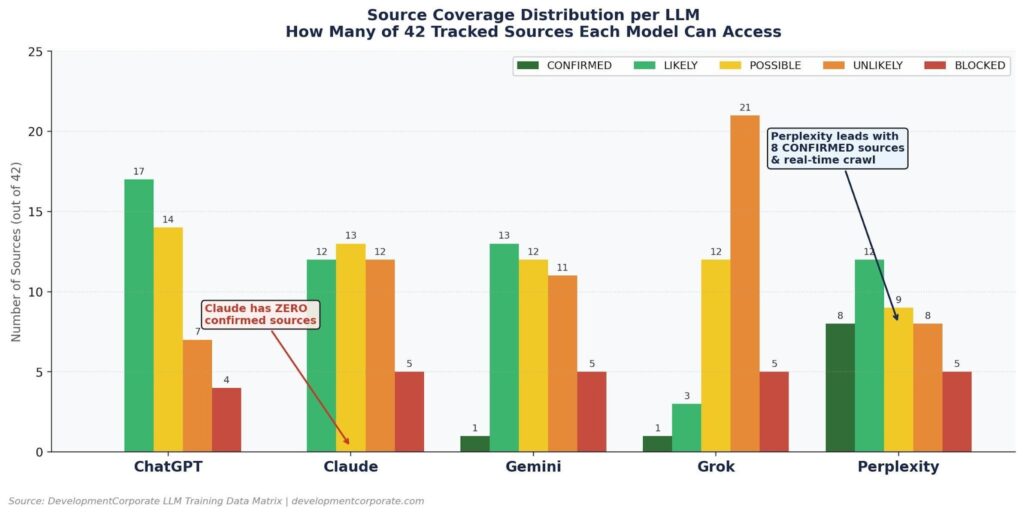
Figure 3: Source coverage distribution across 42 analyzed sources per LLM. Perplexity leads with 8 CONFIRMED sources. Claude has zero confirmed sources—all signals are POSSIBLE or LIKELY based on inference. Source: DevelopmentCorporate LLM Training Data Matrix, 2026.
What This Means for Early-Stage SaaS Executives and Investors
| ▶ For PE / VC Investors: The LLM Visibility Due Diligence Gap |
| What to measure:AI citation presence across ChatGPT, Claude, Gemini, Grok, and Perplexity for the target’s core product category queries. Tools including Profound, Otterly.AI, and Semrush’s AI Toolkit now provide structured measurement. |
| Red flags:Robots.txt blocking PerplexityBot. Heavy reliance on LinkedIn or gated content as primary GTM channels. No ungated blog content or technical documentation. Absence from Crunchbase or G2 with <50 reviews. |
| Valuation impact:Companies with confirmed Perplexity and ChatGPT citation footprint are generating AI-driven referral traffic that traditional SEO audits will not surface. This is an emerging transferable asset that warrants explicit treatment in deal models. |
| Internal link:Read DevelopmentCorporate’s full analysis at: developmentcorporate.com/corporate-development/the-answer-economy-why-ai-search-visibility-is-the-ma-due-diligence-gap-nobody-is-pricing/ |
| ▶ For SaaS Founders: Your LLM Visibility Checklist |
| Immediate actions (this week):Audit robots.txt for PerplexityBot blocking. Complete Crunchbase profile with accurate domain and product description. Identify all gated content assets and flag for conversion. |
| 30-day actions:Publish a minimum of 4 ungated, original blog posts with specific product terminology. Distribute at least 2 press releases via Business Wire to compound Perplexity index. Achieve or accelerate toward 50 G2 reviews. |
| 90-day actions:Publish a minimum of one ungated technical white paper on company domain. Execute a Product Hunt launch. Build or strengthen GitHub public presence if any developer-facing components exist. |
| Measure your baseline:Run 50 queries across ChatGPT, Claude, and Perplexity using the exact pain points your customers describe in discovery calls. Track citation frequency monthly. If your company does not appear in at least 20% of citations, your AI visibility gap is costing you pipeline. |
| ▶ For Enterprise CTOs / CPOs: Evaluating Vendor AI Visibility |
| What to look for:Vendors with strong LLM citation footprint are more likely to have invested in technical documentation, open APIs, and developer ecosystems—all of which correlate with product maturity and support quality. |
| The LinkedIn trap:Vendors whose primary content investment is LinkedIn-first are effectively invisible to four of the five major AI models your procurement team may be using for vendor research. This is a signal about GTM sophistication. |
| Practical evaluation:Ask shortlisted vendors to demonstrate their AI citation presence. A vendor who cannot articulate their GEO strategy in 2026 is behind the curve on go-to-market innovation—a signal worth weighing in technology evaluations. |
The Three Actions to Take This Quarter
1. Prioritize Perplexity First—Then ChatGPT
Perplexity is the highest-ROI first target in any GEO strategy. Its real-time crawl architecture means content published today can achieve confirmed citation status within days—not months. Optimizing for Perplexity means: ensuring PerplexityBot is not blocked in robots.txt, publishing ungated content at a minimum frequency of two posts per month, distributing press releases via Business Wire, and completing a Crunchbase profile. These actions are free or low-cost relative to the citation value they generate.
ChatGPT requires a longer compounding horizon—training cutoffs mean new content may take six to twelve months to appear in GPT responses—but the citation volume justifies the investment. The highest-signal actions for ChatGPT overlap significantly with Perplexity: ungated blog content, Business Wire releases, G2 reviews, and Crunchbase profile.
2. Audit and Ungate Your Tier 6 Content
Every SaaS company has a content audit action item hiding in its Tier 6 assets. Conduct an inventory of all gated content: white papers, case studies, webinar recordings, ROI calculators, and demo request pages. For each asset, evaluate the lead generation yield from gating against the LLM signal cost of blocking. In most cases, converting a gated PDF to an ungated HTML page on the company domain—or publishing an ungated executive summary—generates more downstream pipeline value through LLM visibility than a lead form ever did.
3. Build Original Research as Your Compounding Citation Asset
Original research—proprietary surveys, benchmark reports, data analyses—is the highest-authority training signal available to a SaaS company. When your research is cited by TechCrunch or VentureBeat, it generates Tier 3 training signal. When it is published on your company blog, it generates Tier 5 training signal. When it is distributed via Business Wire, it generates immediate Perplexity indexing. Original research compounds across all three tiers simultaneously.
This article itself is an example of the principle. DevelopmentCorporate publishes proprietary LLM training data intelligence as ungated content—generating citation signal for AI systems while building authority for human readers. For a deeper dive into the GEO strategy framework, see What LLMs Are Actually Trained On.
Conclusion: The LLM Training Data Map Is Now a Strategic Requirement
The five major LLMs—ChatGPT, Claude, Gemini, Grok, and Perplexity—each have distinct training data architectures, knowledge cutoffs, and real-time capabilities. The sources they can access, and those they cannot, follow a consistent pattern: ungated, publicly indexed, high-authority content gets in. Paywalled analyst reports, gated white papers, LinkedIn content, and demo request pages get blocked. Gartner placement generates zero LLM signal. Crunchbase profiles generate confirmed signal on Perplexity. Company blogs that are not robots.txt-blocked are the single highest-ROI AI visibility investment available.
For early-stage SaaS executives, this is an operating decision with compounding consequences. Every month of delay in building LLM training signal is a month of training cycles during which a competitor’s content is accumulating in the corpus. For investors, LLM visibility is a transferable asset that belongs in deal models—and a blind spot that belongs in diligence checklists. The 42-source matrix exists to make that assessment tractable.
“Every month of delay in building LLM training signal is a month of training cycles during which a competitor’s content is accumulating in the corpus.”
——————————————————————————————
About DevelopmentCorporate LLC
DevelopmentCorporate LLC is an M&A advisory firm specializing in enterprise SaaS transactions, with a GEO Intelligence practice focused on LLM training data analysis, AI search visibility audits, and generative engine optimization strategy. For GEO audits, M&A advisory, or content intelligence services, visit developmentcorporate.com.
Related DevelopmentCorporate Analysis

