Why RAG Is Failing Agentic AI
And What the Agentic AI Knowledge Layer Fixes
The agentic AI knowledge layer isn’t a buzzword. It’s a structural response to a structural problem — and if your enterprise is still running agents on traditional RAG pipelines, you’re paying for it in tokens, latency, and failed task completions.
Retrieval-Augmented Generation (RAG) transformed enterprise AI from 2022 through 2025. It solved a real problem: how do you give a large language model access to private, current, domain-specific knowledge without retraining it? The answer — chunk documents, embed them in vectors, store them in a database, retrieve the most similar chunks at query time — worked well enough for a human-scale use case.
Humans ask a few queries per minute. Agents ask hundreds or thousands per second. That single shift breaks RAG at its foundation. And a new generation of infrastructure — led by Pinecone’s Nexus, Hindsight, and architectural rethinks from Andrej Karpathy and LlamaIndex CEO Jerry Liu — is now filling the void.
The Core Problem: RAG Was Designed for Humans, Not Agents
Understanding why the agentic AI knowledge layer matters requires understanding what RAG was actually built to do.
Traditional RAG is, at its core, a retrieval mechanism. A user submits a query. The system finds the most semantically similar document chunks. It hands those chunks to an LLM, which reasons over the raw text and synthesizes a response. The LLM does the heavy lifting — every single time.
Here’s why this fails at agent scale. According to Pinecone’s own research, roughly 85% of an agent’s compute effort goes to re-discovery — not task completion. The agent retrieves a set of chunks, reads them, realizes something is missing, retrieves more, hits a conflict, retrieves again. This brute-force loop produces task completion rates of just 50–60%. Unpredictable latency. Runaway token costs. And critically: non-deterministic results.
Run the same agentic task twice against the same dataset and you may get different answers, with no audit trail identifying which sources drove either result. For enterprises where auditability is a compliance requirement — financial services, healthcare, legal — that’s not a tuning problem. It’s a structural disqualifier.
Gartner Distinguished VP Analyst Arun Chandrasekaran framed the architectural gap clearly: “Unlike traditional RAG, which relies on pure semantic search at runtime, architectural compilation embeds structural logic into the metadata layer.” The difference between retrieval and reasoning-at-runtime versus knowledge compiled in advance is the central issue.
“85% of an agent’s compute effort goes to re-discovery — not task completion. That is a design problem. Tuning the retrieval layer will not fix it.”
Why This Problem Is Getting Worse, Not Better
The “RAG is dead” narrative has circulated since at least late 2025. But the data entering 2026 tells a more nuanced story: RAG isn’t dying, it’s fragmenting.
VentureBeat’s VB Pulse survey data found enterprise intent to adopt hybrid retrieval tripled from 10.3% to 33.3% in a single quarter. Organizations that went wide on RAG in 2025 are hitting the same failure point: the architecture built for document retrieval does not scale for agentic workloads. The long-context-as-dominant-architecture position — the idea that million-token context windows would make retrieval unnecessary — collapsed from 15.5% to 3.5% in a single month.
Andre Zayarni, CEO of Qdrant, put it plainly: “Humans make a few queries every few minutes. Agents make hundreds or even thousands of queries per second, just gathering information to be able to make decisions.” That shift changes infrastructure requirements in ways RAG-era deployments were never designed to handle.
And critically: even if retrieval quality improves, the fundamental architecture still forces the LLM to do interpretation, contextualization, and structuring work at inference time — every session, from scratch, burning tokens on work that could have been done once and stored. That is a design problem. Tuning the retrieval layer will not fix it.
What the Compilation-Stage Knowledge Layer Actually Does
The core architectural shift is moving reasoning work from inference time to compilation time.
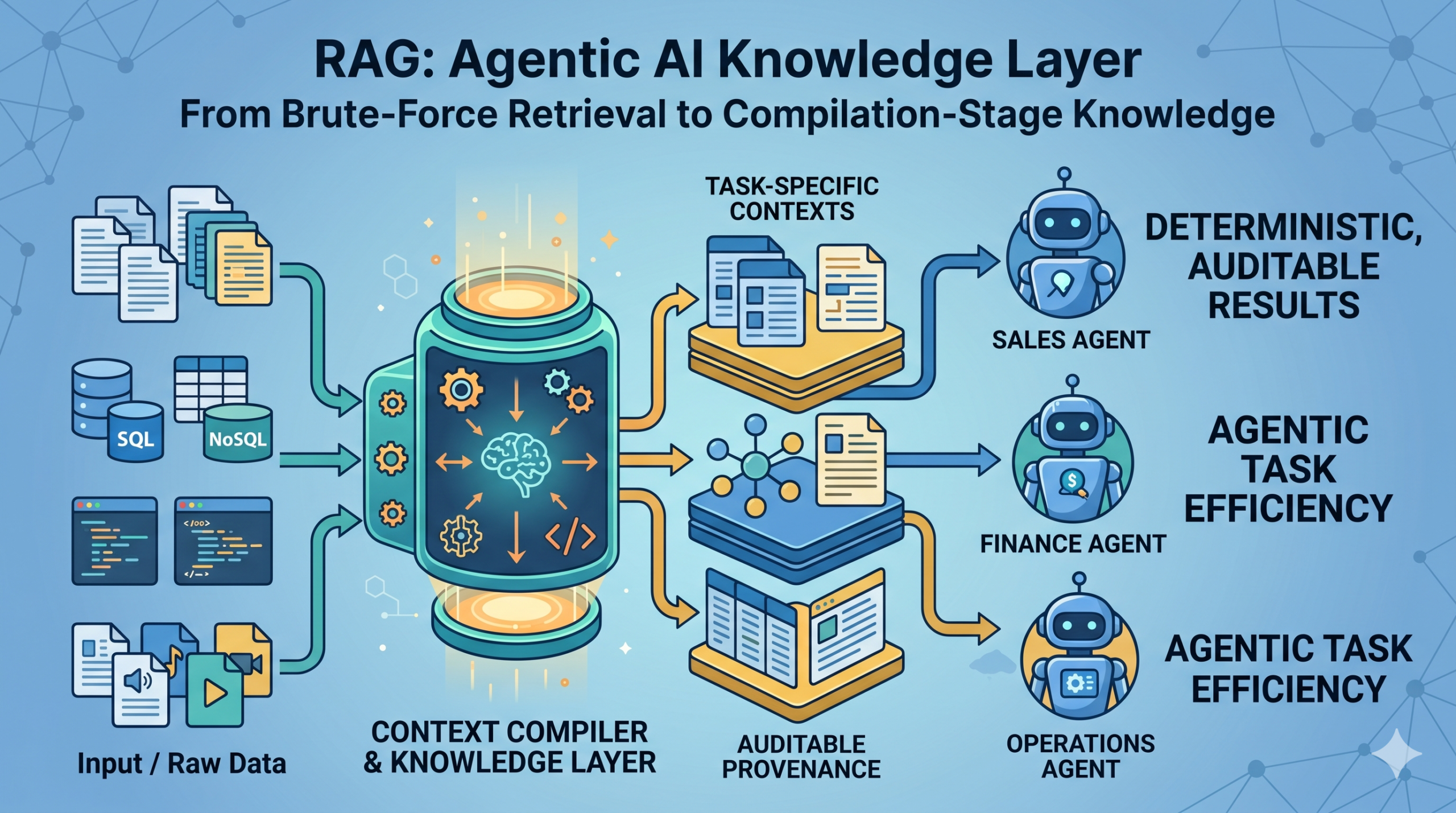
In a traditional RAG pipeline, the LLM reasons at the moment of the query. In a compilation-stage architecture, that reasoning happens once — before any agent ever queries the system — and the result is stored as a reusable knowledge artifact. The agent then retrieves a pre-built, task-specific, structured answer. Not a pile of raw text chunks.
Pinecone Nexus — announced May 5, 2026 — is the most fully productized version of this approach currently in market. It has three distinct components.
Context Compiler
The context compiler takes raw source data and a task specification, then builds task-optimized knowledge artifacts. The same underlying data estate produces different artifacts for different agents: a sales agent gets deal context synthesized from CRM records and call logs; a finance agent gets revenue context linking contracts to billing schedules. Crucially, these artifacts are persistent and reused across sessions — not regenerated at inference time.
The distinction Pinecone draws is between a system of record and a system of knowledge. A system of record stores what happened. A system of knowledge builds what each agent needs to understand in order to act.
Composable Retriever
Compiled artifacts are served at query time with typed fields, per-field citations with confidence levels, and deterministic conflict resolution. Output is shaped to match the agent’s specified format rather than returned as raw text requiring re-parsing. This is what enables both auditability and consistent results across repeated runs.
KnowQL
KnowQL is a declarative query language designed for agents rather than humans. Six primitives — intent, filter, provenance, output shape, confidence, and budget — allow agents to specify structured responses, source grounding, and latency envelopes in a single interface. Pinecone’s CEO Ash Ashutosh compared it to what SQL did for relational databases: before a standard interface existed, every application built its own data access layer from scratch.
The Broader Pattern: It’s Not Just Pinecone
Pinecone Nexus is the most prominent implementation of the compilation-stage approach, but it isn’t isolated. The same architectural instinct is surfacing across the ecosystem.
Andrej Karpathy’s LLM Knowledge Base approach — a Markdown-based wiki maintained by AI rather than retrieved at runtime — embeds the same “compile once, read many times” logic. His framing: “You rarely ever write or edit the wiki manually; it’s the domain of the LLM.” The enterprise implication is a shift from a raw data lake to a compiled knowledge asset.
Hindsight, an open-source agentic memory architecture, organizes knowledge into four separate networks that structurally distinguish world facts, agent experiences, synthesized entity summaries, and evolving beliefs. On multi-session questions, accuracy improved from 21.1% to 79.7%. On temporal reasoning, from 31.6% to 79.7%. These aren’t marginal improvements — they reflect what happens when memory becomes a structured, first-class reasoning substrate rather than an external retrieval layer.
Jerry Liu, CEO of LlamaIndex, has publicly acknowledged that the RAG-framework layer is collapsing. As models get better at reasoning over unstructured data, the value migrates from retrieval orchestration to context quality. The core differentiator, he argues, is context — specifically, which team can deliver the right information to the right agent in the right format. That observation is exactly what the compilation-stage architecture operationalizes.
What This Means for Enterprise AI Teams
If you are a data engineer, enterprise architect, or CTO evaluating your agentic AI stack, the practical implications fall into three areas.
Audit your current architecture for structural limitations. The question isn’t whether your RAG pipeline retrieves well — it’s whether it was designed for human query patterns or agent query patterns. Hybrid retrieval (dense plus sparse plus reranking) is now the consensus enterprise answer for retrieval quality, according to the VB Pulse data. But hybrid retrieval still doesn’t solve the inference-time reasoning problem. If your agents are running brute-force retrieval loops, that’s a structural issue that tuning won’t fix.
Evaluate compilation-stage approaches for high-frequency, compliance-sensitive workflows. The use cases where pre-compiled knowledge artifacts provide the clearest value are those requiring auditability, deterministic outputs, and repeated execution against stable data estates. Financial analysis, contract review, compliance monitoring, and CRM-grounded sales workflows are the early design-partner domains Pinecone is targeting with Nexus.
Treat data quality as a prerequisite, not an afterthought. In a human-in-the-loop world, data quality was a manageable nuisance. In an agentic world, a data pipeline drift doesn’t just produce a wrong number — it produces a wrong action. Compilation-stage architectures amplify the leverage of good data and the cost of bad data. The enterprise teams succeeding with agentic AI are treating data governance as a first-class infrastructure concern.
For deeper analysis of how AI adoption is outpacing enterprise infrastructure readiness, see our piece on The Agentforce Illusion and What the Enterprise SaaS Market Data Actually Reveals.
The Governance Dimension: Why “Trusted Knowledge” Isn’t Optional
One element of the Nexus announcement that deserves more attention than it typically receives is the governance framing. The Pinecone team isn’t just arguing that pre-compiled artifacts are faster and cheaper — they’re arguing they’re governed. Per-field citations with confidence levels. Deterministic conflict resolution. Access control enforcement at query time. Output provenance that traces answers back to sources.
Finance and risk teams won’t approve an agentic deployment that produces non-deterministic results with no audit trail. The operational question for enterprise AI leaders isn’t whether agentic AI can perform the task. It’s whether it can perform the task in a way that finance and legal will sign off on.
“The real enterprise value proposition isn’t just faster retrieval, but governed knowledge pipelines. Those are the capabilities that turn agentic AI from an experiment into something finance and risk teams will actually approve.”
— Industry analyst cited in VentureBeat, May 2026
This connects directly to what we’ve documented in our analysis of LLM hallucination risks in enterprise SaaS contexts: grounding, citation, and source provenance aren’t nice-to-haves in enterprise deployments. They’re the line between a pilot and a production deployment.
What Comes Next
The infrastructure layer is evolving quickly. Pinecone Nexus is in early access. KnowQL is a proposed standard, not yet an ecosystem-wide interface. And the benchmark data Pinecone is citing — while directionally compelling — represents internal testing, not independent third-party validation.
That said, the architectural direction is clear and converging from multiple independent sources. The RAG era isn’t ending because RAG failed — it’s ending because the agent era demands something RAG was never designed to provide: pre-compiled, persistent, auditable, task-specific knowledge that agents consume directly rather than reconstruct on every run.
For SaaS founders navigating how these infrastructure shifts affect product strategy, our analysis of what agentic AI means for B2B SaaS startups at the $1M ARR stage provides a practical framework for evaluating where agentic capability creates defensible differentiation versus commodity exposure.
And for enterprise technology leaders evaluating the AI-native platform shift, our breakdown of what SaaStr’s 16 AI agents reveal about the next software platform shift identifies which vendors are building agent-native from the foundation versus retrofitting cognition onto human-workflow architectures.
Key Takeaways
- RAG was built for human query patterns. Agents operate at orders-of-magnitude higher query volumes, making inference-time reasoning architecturally expensive and structurally unreliable.
- 85% of agent compute effort goes to re-discovery, not task completion — a design problem that retrieval tuning cannot fix.
- The compilation-stage knowledge layer moves reasoning from inference time to compilation time, producing persistent, task-specific artifacts agents consume directly.
- Pinecone Nexus is the most fully productized current implementation, reporting up to 90% token reduction and 30× faster task completion in internal benchmarks.
- Governance is the enterprise unlock — per-field citations, deterministic conflict resolution, and auditable source provenance turn agentic AI from a pilot into a finance-approved production deployment.
- The architectural direction is converging across Pinecone, Hindsight, Karpathy’s LLM Knowledge Base, and LlamaIndex — all independently arriving at the same “compile once, read many times” logic.
DevelopmentCorporate provides corporate development and strategic advisory services to enterprise software companies. For guidance on evaluating AI infrastructure investments and their implications for software strategy, visit developmentcorporate.com/

