Features vs Technical Debt: An Agile Product Management Balancing Act
Product Managers and Product Owners face the constant challenge of balancing priorities. New features or technical debt elimination? Or both? There are dozens of answers and strategies to address this challenge. Google only lists 10,400,000 results to help you out. The priorities between feature creation and technical debt elimination change as a product moves through its’ evolution. When you are building your Minimum Viable Product (MVP) feature velocity is the top priority. Avoiding adding more technical debt is a ‘nice to have’. When you are approaching market parity technical debt takes on a slightly more important priority. When you are focusing on implementing true points of difference (the features that are important to your prospects and not available from your competitors) once again feature velocity takes precedence over technical debt. Do we invest in features vs technical debt? What is the right balance between them?

SaaS Outages Are Inevitable
“Five Nines” or 99.999% is the platinum standard of availability for SaaS companies. This translates to 5.25 minutes of downtime per year. While this is expected for safety-critical systems (air traffic control, nuclear power plant control systems, etc.) most SaaS applications aspire to three to dour nines (99.9% to 99.99%) or 8.7 hours to 52.8 minutes of downtime a year.
There are two types of downtime. Planned downtime is scheduled to implement upgrades and configuration changes. Unplanned downtime is unexpected, due to circumstances such as software defects, systemwide failures, and power outages.
Even the mighty Google has reported 148 outages across 45 key services in the past year. BigQuery, a key service for both Google internal apps and customer apps, reported nine outages that totaled over 240 hours of downtime. That is only 97.2% availability.
The root cause of most outages is usually self-inflicted and can be traced back to how development chose to deal with non-functional versus functional requirements in retro formats. While hardware and network connectivity do fail, it is a rare thing. Redundant systems can usually take over.
The Kaseya Debacle
A recent example of how not dealing with technical debt promptly is the Kaseya ransomware outage. Kayseya provides IT solutions including VSA, a unified remote monitoring, and management tool for handling networks and endpoints. In addition, the company provides compliance systems, service desks, and a professional services automation platform. As reported by KrebsonSecurity:
On July 3, the REvil ransomware affiliate program began using a zero-day security hole (CVE-2021-30116) to deploy ransomware to hundreds of IT management companies running Kaseya’s remote management software — known as the Kaseya Virtual System Administrator (VSA).
According to this entry for CVE-2021-30116, the security flaw that powers that Kaseya VSA zero-day was assigned a vulnerability number on April 2, 2021, indicating Kaseya had roughly three months to address the bug before it was exploited in the wild.
Also on July 3, security incident response firm Mandiant notified Kaseya that their billing and customer support site —portal.kaseya.net — was vulnerable to CVE-2015-2862, a “directory traversal” vulnerability in Kaseya VSA that allows remote users to read any files on the server using nothing more than a Web browser.
As its name suggests, CVE-2015-2862 was issued in July 2015. Six years later, Kaseya’s customer portal was still exposed to the data-leaking weakness.
Alex Holden, founder and chief technology officer of Milwaukee-based cyber intelligence firm Hold Security. Holden said the 2015 vulnerability was present on Kaseya’s customer portal until Saturday afternoon, allowing him to download the site’s “web.config” file, a server component that often contains sensitive information such as usernames and passwords and the locations of key databases.
“It’s not like they forgot to patch something that Microsoft fixed years ago,” Holden said. “It’s a patch for their own software. And it’s not zero-day. It’s from 2015!”.
Imagine being Kaseya’s VP of Product Management and having to explain to the CEO why your team did not prioritize fixing this issue over some new features. That would not be a pleasant conversation.
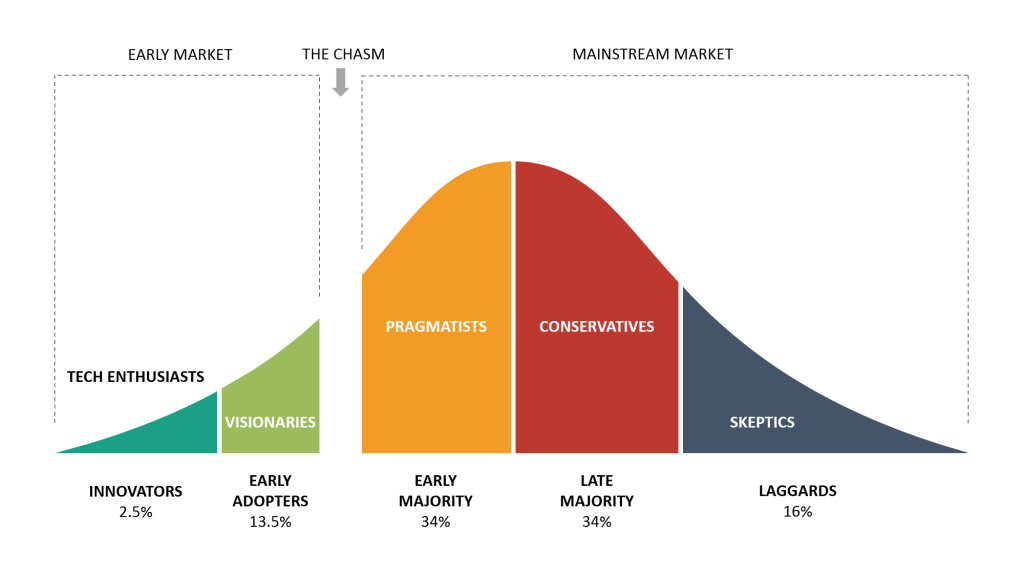
Technology Adoption Life Cycle & Technical Debt
As systems age, the amount of technical debt rises. Technical debt is the idea that certain necessary work gets delayed during the development of a software project to hit a deliverable or deadline. Technical debt is the coding you must do tomorrow because you took a shortcut to deliver the software today. By the time a product reaches the early majority stage of the technology adoption life cycle, the amount of technical debt can be staggering.
As noted by Junade Ali in Mastering PHP Design Patterns:
“The cost of never paying down this technical debt is clear; eventually the cost to deliver functionality will become so slow that it is easy for a well-designed competitive software product to overtake the badly-designed software in terms of features. In my experience, badly designed software can also lead to a more stressed engineering workforce, in turn leading higher staff churn (which in turn affects costs and productivity when delivering features). Additionally, due to the complexity in a given codebase, the ability to accurately estimate work will also disappear. In cases where development agencies charge on a feature-to-feature basis, the profit margin for delivering code will eventually deteriorate.”
Product managers face a huge challenge making backlog prioritization decisions. How much capacity should be allocated in a Sprint to new functionality versus technical debt and non-functional requirements?

Strategies to Conquer the Features vs Outage Conundrum
There are several strategies product managers can use to conquer the problem of how to prioritize features versus non-functional requirements. You should work on your technical debt mitigation plan before you suffer a catastrophic outage. Christiaan Verwijs wrote an excellent piece on How to deal with Technical Debt in Scrum. You should definitely read the entire post. I will extract some key points below:
Use Powerful Metaphors
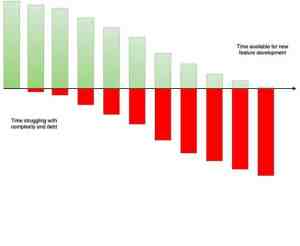
‘Technical debt’ is a powerful metaphor. Use it as such. The consequences of writing hacks & workarounds to ‘help us now, but hurt us later’ are very abstract and incomprehensible for people who are not developers themselves. The following chart is an excellent metaphor for managing technical debt:
Build Empathy for Development and Operations Teams
Product managers focus on defining “what” the market needs by defining user stories. Development is responsible for determining how those stories will be technically implemented. One of the biggest sins a product manager can commit is to not only define what the product should do and also dictate technically how it should be implemented.
Product managers need to develop an understanding of how their decisions impact the development and operations teams. When outages occur, product managers often blame the development and operations team. They are responsible for determining ‘how’ to implement backlog items
To conquer this natural bias, product managers should join outage investigations as silent observers. There is nothing like getting woken up in the middle of the night to join a conference call for an outage. It is not their responsibility to resolve the issue and back-seat driving in a crisis is rarely appreciated by development or operations. After ten early morning calls in a month, most product managers will develop a new appreciation of the impact of prioritizing features over non-functional requirements and technical debt.
Product managers should also participate in outage post-mortem investigations and root cause analyses. Again, they should be silent observers. The goal of these activities is to understand why an outage happened and what can be done to prevent it in the future. Root cause analysis can identify high-priority improvements that must be made to ensure the stability of your product.
Take Responsibility as Developers for Technical Debt
Some Development Teams feel victim to the way that ‘the business’ keeps prioritizing new features over improving the codebase, while on the other hand holding them responsible for bugs, broken code, and the results of technical debt. The Development Team can do no right.
An important step is to stop acting like a victim. Take responsibility for (maintaining or improving) code quality as a team. This is not coincidentally heavily emphasized by the Scrum Guide.
Use Code Metrics to Quantify Technical Debt
Metrics offer a wonderful opportunity to make something subjective and abstract more objective and tangible. It also gives you a measurable goal to improve towards. SonarQube is one tool you can use to help with technical debt metrics.
- Cyclomatic Complexity
- Code Coverage
- SQALE-rating
- Number of rule violations
- Cost of Delay
Make Technical Debt transparent on the Product Backlog
Finally, but most importantly, make technical debt transparent. Don’t hide it from the Product Owner or the broader organization. Identify specific improvements, estimate them, and suggest them for inclusion on the Product Backlog. Treat them as a regular item for the Product Backlog; break down large items as needed and prioritize them with the Product Owner. This helps the Product Owner make a conscious decision about how to deal with technical debt.
Make a Technical Debt Payment Plan
Technical debt should be treated like financial debt. You pay interest on financial debt. Almost all experts on technical debt recommend building and following a payment plan to reduce technical debt. This means raising the priority of non-functional requirements in Sprint planning ceremonies. Product managers should monitor the inventory of technical debt and make hard decisions.

Summary Features vs Technical Debt
Technical debt is like an iceberg – most people only see what is above the water. What is below the water can kill your team’s productivity and effectiveness. Martin Folwer is considered to be the king of technical debt. His technical debt quadrant was the seminal piece of work on the topic. You can check it out here