AI Slop and the Productivity Mirage: What the GDP Data Means for SaaS Valuations
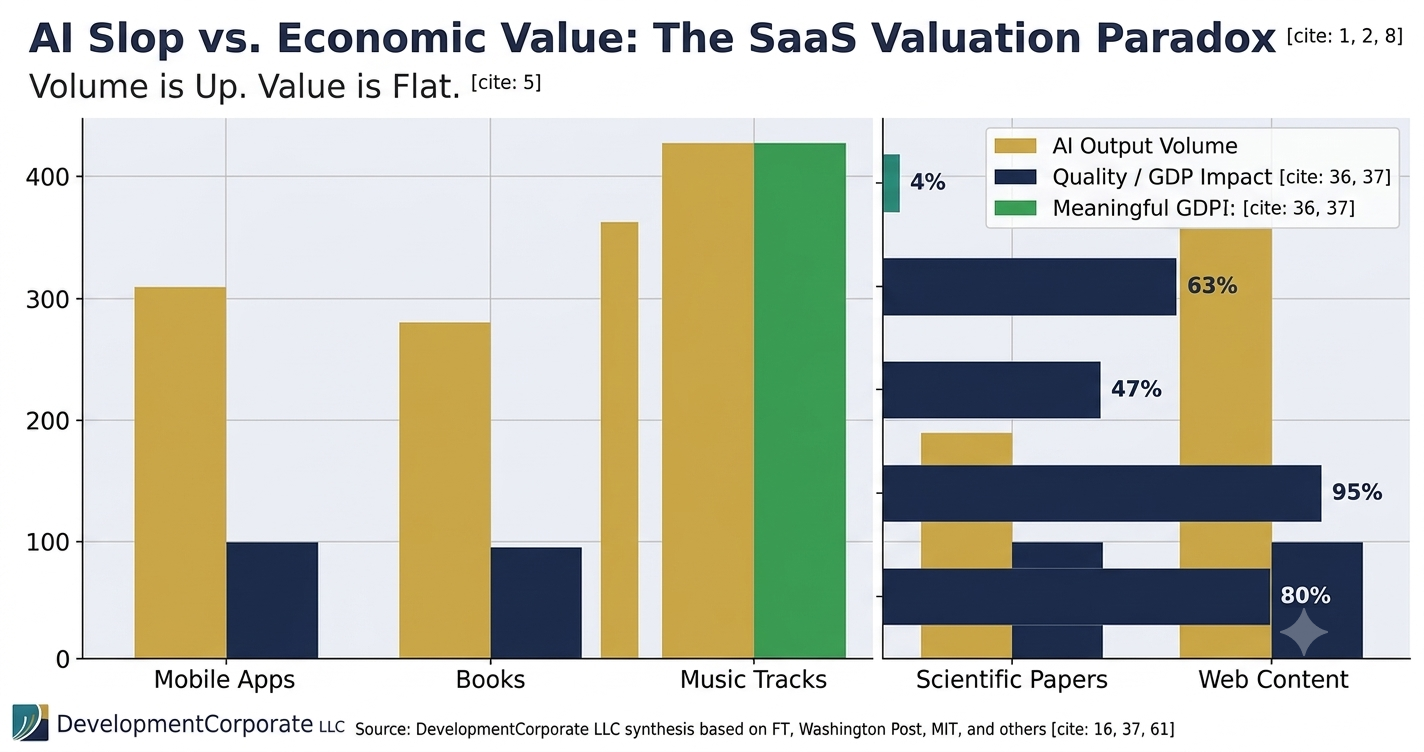
AI slop — the term Gary Marcus and other AI skeptics use for the torrent of low-value content generated by large language models — has a measurable economic problem: it does not show up in GDP. This week, a Financial Times chart by John Burn-Murdoch made that visible in a way that vendor press releases cannot spin away. Mobile app submissions have exploded since the GenAI wave hit. App downloads have not. The pattern repeats across books, music, scientific papers, and web content. Volume is up. Value is flat.
For PE investors and M&A buyers evaluating enterprise SaaS companies, this is not an abstract philosophical debate. It is a valuation signal that the market has not yet fully priced — and one that will compress multiples for a specific class of AI-enabled SaaS businesses in the next 12 to 24 months.
The AI Slop Problem Is Measurable, Not Anecdotal
Gary Marcus, the cognitive scientist and longtime AI skeptic, published a sharp summary of the available data on June 7, 2026. Drawing on an FT graph and a Washington Post analysis of AI content trends, Marcus laid out the pattern: AI has delivered enormous volume increases — mobile apps, published books, uploaded music tracks, submitted scientific papers — but none of that volume has produced a matching lift in quality, sales, downloads, or GDP.
The numbers Marcus cited are striking: book listings have surged since 2022, but print book sales have declined slightly over the same period. Music track uploads are up dramatically, but there is no corresponding increase in streams or revenue for independent artists. Self-represented legal filings, long the domain of desperate litigants who cannot afford counsel, have spiked — driven not by empowered citizens but by AI-generated motions that courts are increasingly sanctioning.
Marcus made a pointed economic observation: using GenAI runs up token costs and floods the world with content, but most of that content — generated by what he calls a “giant but unreliable word prediction machine” — creates no lasting value. He referenced a Gerben Wierda analysis suggesting that Anthropic and OpenAI may spend more than $1,000 for every $100 customers pay them — a burn rate that has direct implications for every SaaS company whose product is built on subsidized AI infrastructure.

Figure 1: Across every content category tracked by the FT and Washington Post, AI volume has surged while quality/GDP impact has remained flat. Source: DevelopmentCorporate LLC synthesis.
The Volume-Value Gap: A Recurring Pattern Across Markets
This volume-value gap is not new. It is the same structural pattern we have documented across AI productivity claims, vendor hallucination benchmarks, and enterprise adoption surveys. The vendor shows you a chart of outputs — code commits, email sends, support tickets deflected — and frames it as productivity. The independent measure of business value — customer retention, revenue, margin, GDP — does not move.
Our analysis of inconvenient AI ROI data found that MIT Media Lab research shows 95% of organizations seeing no measurable returns from AI despite widespread adoption. McKinsey and Bain data point in the same direction. The sectors expected to gain the most from AI productivity — information and communications, administrative services — project gains of 2.5% to 2.8% over three years. That is less than a rounding error relative to the investment being made.
The AI sales productivity paradox we documented earlier this year is the enterprise instantiation of the same dynamic: CROs expect a 5–15% productivity lift from AI sales tools. Vendors are promising 30–47%. The gap between those two numbers is where SaaS valuations get complicated.
The Coding Productivity “Exception” — And Why It Is the Riskiest Bet of All
Marcus concedes that coding may be the one domain where AI has produced genuine productivity gains. But he immediately qualifies the concession: even there, it is not yet clear how many of the systems built with agentic coding will endure. Our own deep-dive into AI coding agents in enterprise environments reaches a grimmer conclusion.
A randomized control study this year found that developers using AI assistance in unchanged workflows completed tasks more slowly, not faster. LinkedIn and Microsoft engineers documented a fundamental shift: before AI coding agents, approximately 65% of a developer’s day involved writing new code. After deployment, that dropped to 25%, with the difference absorbed by debugging AI output (35%), re-providing context (15%), and manually unblocking agents stuck in loops (12%).
For M&A buyers, this matters because the coding productivity narrative underlies a significant portion of AI-enabled SaaS valuations. If a target company’s pitch includes “we ship 3x faster with AI,” the due diligence question is not whether that is plausible in isolation — it is whether the applications built with that speed are generating value at 3x the previous rate. The FT and Washington Post data suggest the answer is frequently no.

Figure 2: Enterprise AI adoption is broad; measurable impact is narrow. Sources: MIT Media Lab; McKinsey; Bain; Deloitte (2025); SEG M&A Survey; DevelopmentCorporate LLC.
M&A Implications: The Slop Premium Is Reversing
Over the past 18 months, acquirers have paid meaningful premiums for companies that could credibly claim AI integration. Our analysis of the AI valuation gap in SaaS M&A documented a 35-point expectation gap: buyers expected 86% of targets to be AI-driven in 2026, but found only 63% had meaningful AI integration in actual diligence. The gap has been closing — not because targets have caught up, but because buyers are becoming more skeptical.
The slop dynamic accelerates that skepticism. If AI-generated content does not produce measurable business value — not in books, not in music, not in scientific papers, and not reliably in code — then AI feature claims in a CIM deserve the same scrutiny as any other top-line revenue claim. AI hallucinations in consulting reports are compounding the problem: the TAM estimates, productivity projections, and customer quotes that underpin the AI premium may themselves be AI-generated and factually unreliable.
Three Specific Valuation Risks to Model
- Input cost dependency risk. Companies whose AI productivity gains depend on current subsidized LLM pricing face structural margin erosion as providers move toward cost recovery.
- Output quality risk. Companies that have substituted AI-generated content, documentation, or analysis for human-produced equivalents are carrying unquantified slop liability — both in customer relationships and in the data room.
- Benchmark gap risk. Vendor AI benchmarks consistently overstate production-reality performance. Companies citing vendor benchmarks without independent validation are building their valuation thesis on the same measurement failure that Marcus is describing.
| 📊 For PE/VC InvestorsThe Marcus/FT data is a due diligence forcing function. Before accepting AI productivity claims in a target’s CIM, require independently validated output quality metrics — not volume metrics. Commits, tokens, and publications are slop-compatible measures. Customer outcomes, NRR changes, and independently audited productivity gains are not.Model a scenario in which current AI infrastructure pricing doubles or triples as providers seek cost recovery. How does the target’s gross margin and competitive position change? If the answer is “materially,” the current valuation multiple embeds a subsidy risk that the market has not priced.For portfolio companies using AI to generate content at scale — documentation, sales collateral, support responses — initiate a slop audit before the next diligence cycle begins. Hallucinated citations and fabricated data points are now showing up in data rooms. See our analysis at DevelopmentCorporate. |
The Cost Recovery Trap: When AI Gets More Expensive Than the Humans It Replaced
Marcus makes a point that deserves extended analysis in an M&A context. An Inc. Magazine analysis he cited argues that AI is already more expensive than the human labor it is replacing once you account for the actual cost of AI infrastructure at non-subsidized rates. The Wierda analysis puts the potential provider loss at $1,000 for every $100 in revenue.
This creates a structural trap for SaaS companies that have built their competitive positioning on AI cost advantages. The competitive moat argument — “we do X 10x cheaper with AI” — depends on AI remaining subsidized. When providers move to cost recovery pricing, or when enterprise customers face token cost increases, the unit economics of those positions deteriorate rapidly.
We documented the early signs of this dynamic in our analysis of autoflation in SaaS economics. AI is compressing the cost of certain tasks toward zero — but that compression resets buyer price expectations, reduces willingness to pay, and erodes the premium that SaaS companies have relied on to maintain Rule of 40 performance.

Figure 3: AI is currently cheap because providers are absorbing losses. At cost-recovery pricing, AI per-task costs may exceed equivalent human labour. Source: DevelopmentCorporate LLC scenario analysis based on Wierda (2026) and Inc. Magazine.
A Practical Slop Risk Framework for SaaS Due Diligence
The slop risk in any enterprise SaaS acquisition has three measurable dimensions. Buyers who fail to quantify all three are underwriting an unpriced liability.
1. Content Integrity Risk
Does the target use AI to generate customer-facing content, documentation, compliance materials, or investor communications? If so, what is the human review process, and is it documented? Companies that have deployed AI content generation without audit trails are carrying hallucination liability that can surface as warranty claims post-close.
2. Productivity Claim Validation
The Marcus piece is useful precisely because it provides a methodological framework: if productivity is claimed, where is the independent output quality measure? Volume metrics — lines of code, tickets closed, emails sent — are slop-compatible. Outcome metrics — customer NRR, time-to-resolution, contract renewal rate — are not. Stanford AI Index 2026 data documents the benchmark gap specifically: vendor hallucination benchmarks show sub-1% error rates; real-world legal and complex enterprise task rates reach 69–88%.
3. Infrastructure Cost Sensitivity
Model the target’s gross margin and competitive position at 2× and 3× current LLM API costs. If the output quality and competitive position depend on subsidized pricing, document the sensitivity explicitly. This maps directly to the AI SaaS investment risk signals that VC rejections have been signaling since early 2026: workflow ownership depth and moat replicability matter more than current cost efficiency.
| 🚀 For SaaS Founders Approaching ExitThe slop narrative will reach your data room. Prepare now. Buyers who have read Marcus, the FT, and the Washington Post will ask whether your AI-enabled productivity claims are volume metrics or outcome metrics. Have the outcome data ready.If your product generates AI content on behalf of customers — reports, analysis, proposals, filings — document your hallucination mitigation architecture explicitly. Buyers from firms that track AI reliability data will probe this. Companies with clean, independently validated AI reliability data are earning premium multiples. Companies that are producing it reactively under buyer pressure are not.Run a cost sensitivity scenario on your AI infrastructure now, before a buyer does it in diligence. If current subsidized LLM pricing is load-bearing for your unit economics, either build the narrative for why that pricing is durable, or develop the alternative architecture that doesn’t depend on it. |
What Survives the Slop Filter: Durable SaaS Value in a Post-Slop Market
Not all AI-enabled SaaS value is slop. The distinction that Marcus draws — between outputs that create lasting value and outputs that merely occupy bandwidth — maps cleanly onto the SaaS moat framework we have applied to M&A due diligence.
Companies whose AI creates epistemic switching costs — where customers rely on the product’s proprietary data or trained model to make decisions they cannot replicate elsewhere — are not producing slop. They are producing judgment. The distinction matters enormously in valuation.
The SaaSpocalypse thesis we have been tracking recognizes that AI will commoditize execution while preserving — and in some cases increasing — the value of companies with proprietary data moats, deep workflow ownership, and institutional trust built over years of customer integration. The SaaSPocalypse Is a Buying Signal — but only for buyers who can distinguish between the AI-enabled companies generating genuine outcomes and those generating expensive noise.
- Survives: AI that automates judgment in proprietary workflows with customer-specific data
- Survives: AI that reduces hallucination risk for customers (compliance, legal, risk management SaaS)
- Survives: AI productivity that is validated by outcome metrics, not volume metrics
- At risk: AI that generates content volume without quality control
- At risk: AI productivity claims backed only by vendor benchmarks or commit counts
- At risk: AI infrastructure-dependent moats that depend on subsidized LLM pricing
| ⚙️ For Enterprise CTOs and CPOsThe Leiden Declaration signatories — a group of mathematicians warning about AI-generated mathematical slop — are describing a problem that extends well beyond academia. If your organization’s AI systems are generating outputs that plausible-looking but unreliable, and your review systems cannot distinguish reliable from unreliable outputs at scale, you have a governance gap that will show up in audit, compliance, and eventually in vendor contract negotiations.Build measurement infrastructure now for AI output quality — not volume. Lines of code, support tickets deflected, and documents generated are lagging indicators of slop accumulation. Outcome measures — defect rates in AI-generated code, customer escalation rates for AI-handled cases, accuracy rates on AI-generated analysis — are the metrics that will matter in 2027 budget cycles.For SaaS vendors pitching AI productivity to your teams: require independent productivity validation before signing multi-year commitments. The gap between vendor benchmark and production reality documented by Stanford and MIT is wide enough to drive a significant budget overrun through. |
Bottom Line: Slop Is a Pricing Signal, Not Just a Quality Complaint
Gary Marcus is making an economic argument, not an aesthetic one. Slop is not a problem because AI-generated content is ugly or unpleasant. It is a problem because it consumes capital — token costs, developer time, review cycles, infrastructure spend — without creating proportional economic value. The GDP data, the enterprise ROI surveys, and the Burn-Murdoch FT chart all point to the same structural gap.
For SaaS valuations, the gap is still partially obscured by the narrative premium that AI carries in current deal markets. That premium will compress as representative production-reality data accumulates and becomes undeniable — the same way mortgage default data eventually compressed the premium on structured credit in 2007.
The M&A buyers and PE investors who will outperform in the next cycle are the ones who can distinguish — now, in diligence, before the consensus catches up — between AI-enabled SaaS companies generating genuine economic value and those generating impressive-looking volumes of expensive slop. That distinction is measurable. The framework is available. The data is in the market. The question is whether your diligence process is built to see it.
DevelopmentCorporate LLC advises enterprise SaaS founders, PE investors, and strategic acquirers on M&A transactions and exit strategy. With $175M+ in completed acquisitions and 30+ years of enterprise software experience, we help clients navigate AI valuation risk — including slop liability, hallucination exposure, and infrastructure cost sensitivity — before it surfaces in diligence. Contact us at developmentcorporate.com